If the models of artificial intelligence aren’t explainable, then specialists (e.g. in medicine) must fully trust the technology, even though their signature is below the diagnosis. We are working on a system in our Laboratory which will be able to answer what forms the basis of its predictions. Monika Redzisz talks to Piotr Sobecki, the head of the Applied Artificial Intelligence Laboratory
Monika Redzisz: What does the Applied Artificial Intelligence Laboratory team, working at the National Information Processing Institute*, do?
Piotr Sobecki**: The application of AI in medicine, among others. We standardize the procedures, work on image analysis methods and create the artificial intelligence models to support diagnostics. For example, we analyze the problem of prostate cancer diagnosis using the magnetic resonance imaging (MRI). It’s the second most common cancer in men – it’s estimated that every sixth man will be diagnosed with prostate cancer during their lives.
Unfortunately, its diagnosis is complicated.
Why?
For several reasons. The screening for prostate cancer is the measurement of PSA in the blood, that is a certain enzyme. Its high level indicates some sort of anomaly. In this case, further diagnostics is required. On the basis of the magnetic resonance images, a radiologist will have to decide, whether the findings are malignant. Subsequent decisions will depend on that, e.g. whether to perform a biopsy. In the case of prostate exam, a biopsy is neither easy, nor comfortable for a patient. It involves the gathering of the material for screening from several to a dozen incisions made during the screening.
When, based on a magnetic resonance imaging, we will have precise enough methods to evaluate potentially malignant lesions, we’ll be able to significantly reduce the number of patients who are referred to biopsies.
At what stage are the works currently on?
We’re creating the tools supporting this process. One of them is a deep neural network which determines the probability of a malignant change based on MRI of the prostate. Its effectiveness is estimated to be around 85 percent which is close to the effectiveness of a radiologist. The algorithm evaluates the significance of a particular change on the percentage scale (for example:10, 60, 80 percent). It’s analogus with PI-RADS classification used by specialists.
And what if the probability of finding being malignant is sixty percent? What does a radiologist do with it?
Exactly. In order to understand it, we need to take a step back, that is define what a diagnostician does. Let’s imagine a situation where we clean up our e-mail inbox and we evaluated the e-mails, if they’re spam or not. We’re going to rely on our intuition to do it on the spot. Having the system for such a classification, we are given the information that the system assesses there’s a sixty percent probability that a particular e-mail is spam. This is an extremely simplified description of a diagnostician’s job.
He got a result from some machine: sixty percent. But why sixty, exactly? He doesn’t know. How is he supposed to use this information? Sixty percent probability isn’t enough, it doesn’t tell us anything, because it’s close to a random decision. But even if it was – let’s say – eighty percent, then a doctor has a problem too, because there isn’t enough information, why artificial intelligence has made such a decision.
We need a lot of data, while the biggest accessible database of prostate imaging has only three hundred fifty cases
Currently, it’s the biggest challenge for scientists working on artificial intelligence: how to create explainable models that aren’t black boxes, meaning the ones which are capable of answering what is the basis of system prediction.
At our laboratory, we are working on an artificial intelligence-supported system (eRADS) which will be able to do that. We have specified over a hundred parameters that have been partly converted to decision tables. In the final version of the tool it’s going to look like this: first, the system will perform an automatic analysis of medical images. A doctor will get a generated report of the assesment in the PI-RADS standard. His job is the verification of the structured medical report. Currently, such a description is in the form of a written report which prolongs diagnostics and narrows the scope of the diagnosis.
If at a certain stage, a physician has doubts concerning the automatically generated report, he can check where did that particular result come from – see which intermediate variables were calculated and modify them however he wants. He can find out, for example, that the algorithm in one point determined that a lesion is moderately hypointense, while he thinks it’s significantly hypointense. He will have over a hundred calculated parameters at his disposal, with full control over them.
Entering the black box…
Yes. If the models aren’t explainable then the specialists must fully trust the technology, even though they’re the ones leaving their signature below the diagnosis. People introduce hybrid methods, of course. For example, the algorithms highlight the areas of benign transformations so that depending on the coloration it’s easier to evaluate it. Then, a color can point to a probability that a particular transformation is malignant. This really helps a specialist to determine what can influence the model prediction.
Where do you get the data for algorithm training?
Exactly, that’s the problem. We need a lot of data, and currently the biggest database of prostate imaging counts only 350 cases.
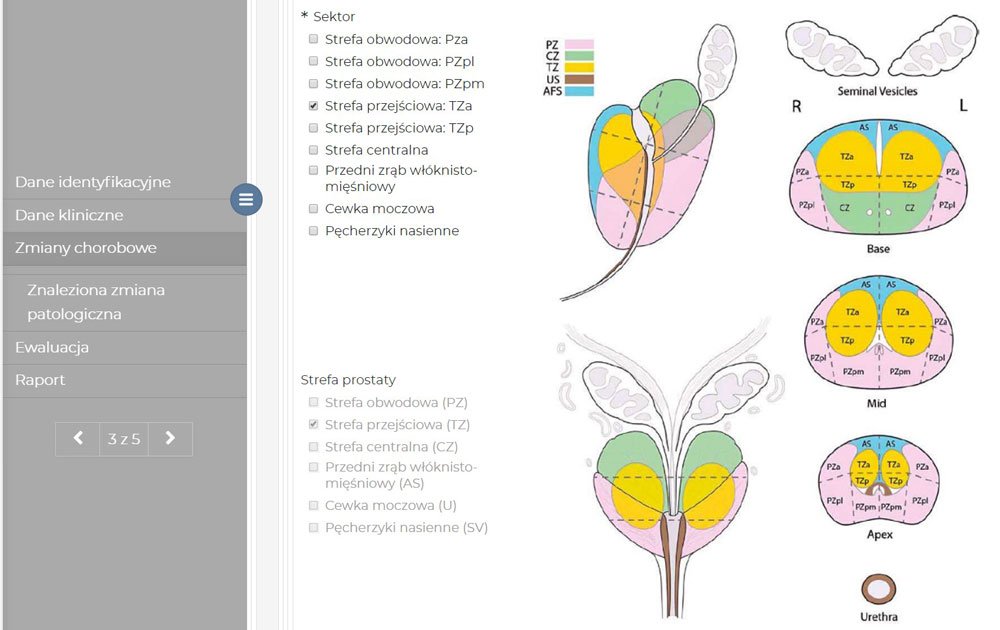
In order to train the models, we had to artificially augment the data set – introduce certain distortions and image noise. It’s a common practice in a situation when there’s not enough data for AI training. Our networks consist of several million parameters and we have only three hundred fifty cases at our disposal. The network is capable of memorizing each pixel. The extension causes the network to ignore the details which identify a concrete case and aren’t significant for modeled issues.
Artificial intelligence models are as good as the data they learned from. It’s about their quantity, meaning how many cases are in a given set, as well as quality.
Is there no way to collaborate with hospitals?
We have a collaboration with the department of radiology at the Centre of Postgraduate Medical Education in Warsaw. The problem is such that research centers usually only have the imaging data and its reports. A patient comes, gets an MRI, gets the results, and goes out into the world. We don’t get the feedback as to what happens to them later. Patients come and go, and we have a problem to integrate their images and reports with a subsequent health status (e.g. biopsy results). What’s more, even though the international radiological diagnosis standard PI-RADS (Prostate Imaging and Reporting and Data System) has been around for a couple of years, every physician essentially has their own way of reporting. Reports written in this form are difficult to convert into a data set suitable for artificial intelligence.
This gives a sizeable margin of subjectivity…
Yes. A diagnostician determines the characteristics of detected finding. Is the lesion homogeneous or heterogeneous? Homogeneous or not? Every doctor has their own sense of this homogeneity; one means it’s homogeneous, another that it’s not. Or: how to subjectively determine the brightness? Is the brightness weak, moderate or intensely hypointense? Moderately dark or deeply dark? The decision about the diagnosis depends on it. Of course, sometimes the case is obvious and there’s nothing to think about. But everything in between is up for discussion.

We propose our proprietary solution to this problem: we have prepared a special tool for radiologists. The doctor’s task will involve the definition of traits on a form instead of writing it by hand. During their work, high-quality data sets are created which will be used for research on the malignant lesion assesment standards. Thanks to this approach we get a beautiful database for artificial intelligence algorithms, and on the basis of the filled out form a structured report is automatically generated.
We’ve just started our works. We gather thirty cases for assesment by six radiologists: three of them experienced and three inexperienced. Retest is conducted after a month. It’s interesting also from a psychological point of view: we will also conduct this study in collaboration with the cognitive psychologists at the SWPS University of Social Sciences and Humanities. Will significant differences arise between radiologists? Will a physician assess the case after a month the same way as they did the first time? I’m really curious what’s going to be a result of this. My experiences, apart from computer science, cover psychology too. While I was studying, I worked on a tool to study the susceptibility to optical illusions. (VIS – Visual Illusion Simulation), because we’re all born with a certain degree of susceptibility. And now the question: how susceptible to illusion are radiologists?
When, based on a magnetic resonance imaging, we will have precise enough methods to evaluate potentially malignant lesions, we’ll be able to significantly reduce the number of patients who are referred to biopsies.
How do the brave ones feel, the ones who volunteered to take part in the project? Are they afraid?
Possibly. People don’t like to discover that they could be wrong. But they realize the system will serve as a support for radiologists.
But also a danger. Won’t this method soon force them out of work? Or, in the least, won’t they lose their autonomy and a professional intuition?
I think it’ll be dramatically different. There’s a shortage of radiologists. The MRI machines can work 24/7, but who’s going to describe the scans? There are too few physicians. The system will make their job much easier. They will be able to describe more scans at the same time, while their job comfort and the quality of their assesment and reports will increase.
Is there a visible generational difference in the approach to these methods?
Sure. Studies show that experienced specialists often think: ‘’I know what I’m doing. I’ve been doing this for so long. I know my effectiveness. Why would I need some tool, telling me what to do?’’ The younger generation – the opposite – they’re open to the introduction of such solutions.
Unfortunately, thirty cases is a bit low. If we had five hundred, then it would be something. But such a data set costs. That’s why we’ve applied for a grant to the National Science Centre for the collaboration with the Oslo University Hospital. As part of the collaboration, data sets from Polish and Norwegian research centers would be integrated, containing notes on a designed tool. This would be the biggest and the most precisely described open source mpMRI prostate data set that exists in the world.
I’m most pleased about the fact that the eRADS methodology we come up with for prostate cancer MRI diagnosis will be a fantastic foundation to work on other neoplastic diseases.
*The National Information Processing Institute – State Research Institute is the publisher of the Artificial Intelligence web portal
**Piotr Sobecki – the head of the Applied Artificial Intelligence Laboratory at the National Information Processing Institute – State Research Institute. He is a PhD candidate in computer science (Warsaw University of Technology, Faculty of Mathematics and Information Science), MSc in computer science (Polish-Japanese Academy of Information Technology) and psychology (SWPS University of Social Sciences and Humanities). In 2018, one of the experts preparing the tenets for the development of artificial intelligence in Poland. His scientific interests are: medical information science, deep learning, computer image recognition, signal processing and cognitive psychology.
Przeczytaj polską wersję tego tekstu TUTAJ