Naukowcy z MIT dali nam do ręki broń przeciwko artykułom wygenerowanym przez sztuczną inteligencję
W ostatnich latach nastąpił przełom w technologii przetwarzania języka naturalnego. Powstają coraz bardziej wysublimowane systemy, które produkują teksty często nieodróżnialne od tych napisanych przez ludzi. Dobrym przykładem jest stworzony przez OpenAI algorytm GPT-2, który na podstawie kilku słów jest w stanie napisać wiarygodnie brzmiący, całkowicie wyssany z palca elaborat, zachowując przy tym styl oryginału.
Całkowicie naturalne wydają się obawy o wykorzystanie tej technologii w złej wierze. Nietrudno wyobrazić sobie tworzone przez automat recenzje produktów i usług, posty szkalujące osoby czy grupy społeczne, wreszcie fake newsy na potrzeby walki politycznej.
W czerwcu eksperci z Global Pulse, inicjatywy ONZ, pokazali, że tego rodzaju system można stworzyć przy użyciu publicznie dostępnych technologii w 13 godzin.
W tej sytuacji konieczne jest stworzenie narzędzi do wykrywania automatycznie wygenerowanego tekstu. O tej potrzebie mówiła w rozmowie z nami dr Aleksandra Przegalińska. Uniwersytet Harvarda we współpracy z MIT-IBM Watson AI Lab zaprezentowali niedawno system, który przy użyciu prostych metod statystycznych ma pomóc rozpoznać tekst wygenerowany przez bota.
Modele przetwarzania języka naturalnego bazują na statystycznych wzorcach występowania słów w tekstach, a nie na znaczeniu wyrazów i zdań. To je odróżnia od tekstów pisanych przez ludzi.
GLTR może się okazać przydatnym narzędziem dla dziennikarzy, researcherów i innych krytycznie myślących konsumentów internetowych treści
GLTR jest wyposażony w interfejs, który pozwala na wizualizację przewidywalności tekstu. Wyrazy w badanym fragmencie są podświetlone na różne kolory, korespondujące z prawdopodobieństwem ich wystąpienia w danym miejscu. Zielone mają największą szansę na wystąpienie, podczas gdy fioletowe – najmniejszą. Słowa zaznaczone na czerwono i żółto plasują się pomiędzy. Częstsze występowanie słów oznaczonych na zielono oznacza, że tekst jest przewidywalny i prawdopodobnie został stworzony przez algorytm. Występowanie w badanym fragmencie słów zaznaczonych na fioletowo wskazywałoby na ludzkie autorstwo.
Narzędzie o nazwie GLTR (Giant Language model Test Room) wykorzystuje ten fakt i ocenia statystyczne prawdopodobieństwo wystąpienia sekwencji słów, czyli przewidywalność tekstu. Jeśli tekst ma wysoki stopień przewidywalności, prawdopodobnie został napisany przez maszynę.
Narzędzie jest publicznie dostępne tutaj, a my postanowiliśmy je przetestować. Najpierw daliśmy mu do analizy wycinek stworzony przez wspomniany wyżej algorytm GPT-2. Pierwsze dwa zdania tekstu stanowią napisane przez „ziarno”, na podstawie którego GPT-2 wygenerował resztę. Oto, co na ten temat myśli GLTR:
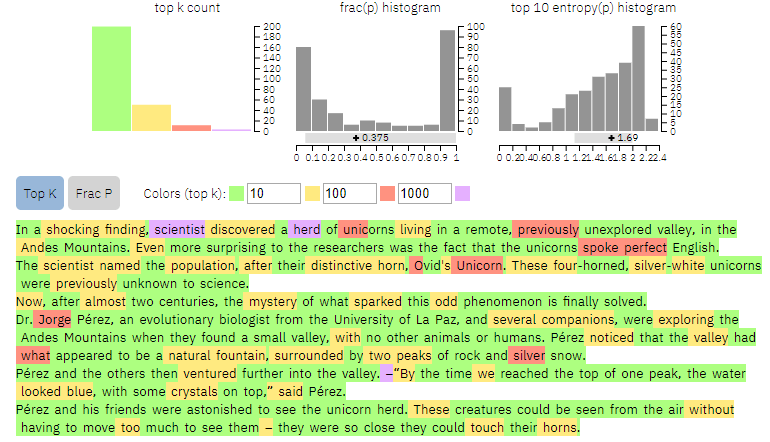
Źródło: MIT IBM-Watson AI Lab
Jak widzimy, kolor fioletowy sugerujący niską przewidywalność znajdziemy praktycznie tylko w części stworzonej przez człowieka. Niewiele jest też wyrazów podświetlonych na czerwono.
Tej samej próbie poddaliśmy fragment „Przygód Tomka Sawyera” Marka Twaina. Oto rezultat:
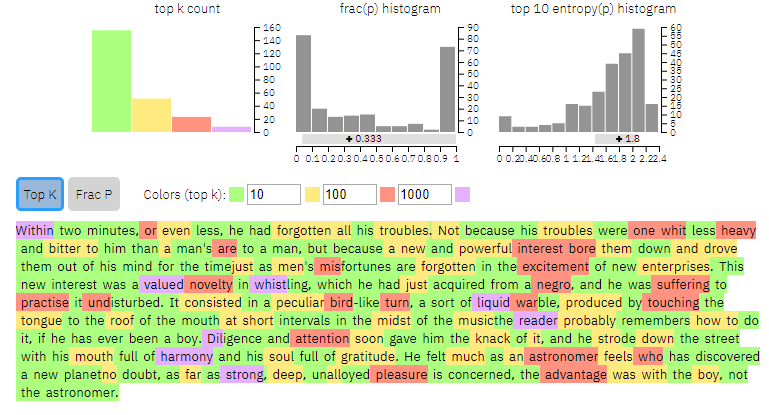
Źródło: MIT IBM-Watson AI Lab
Widać wyraźną różnicę – tekst Twaina jest wyraźnie mniej przewidywalny.
Twórcy GLTR przeprowadzili testy skuteczności swojego narzędzia. Badani zostali poproszeni o odróżnienie tekstu pisanego przez człowieka i generowanego przez sieć neuronową. Bez wsparcia GLTR udało im się to w 54 procentach przypadków. Użycie narzędzia pozwoliło im na poprawne wskazanie w 72 procentach przypadków.
GLTR może się okazać przydatnym narzędziem dla dziennikarzy i researcherów. Warto też, by korzystało z niego jak najwięcej osób. Niestety w dobie postprawdy i fake newsów tego rodzaju system powinien znaleźć się w pasku zakładek każdego krytycznie myślącego konsumenta internetowych treści.