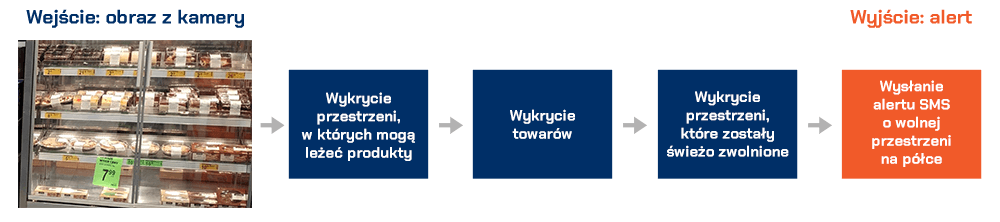
Tym razem zajmiemy się wykrywaniem obiektów za pomocą sieci neuronowych
Ostatnio coraz bardziej popularne stają się autonomiczne sklepy (bez obsługi), niech więc taki sklep będzie przykładem dla naszego eksperymentu myślowego. Będziemy chcieli wykrywać przedmioty na wystawie takiego sklepu, a gdy jakiś zniknie (gdy zwolni się miejsce) – otrzymać stosowne powiadomienie SMS.
To może wydawać się dość skomplikowane, ale zbudowanie wersji roboczej takiego rozwiązania z głęboką siecią neuronową jest w rzeczywistości dość szybkie i relatywnie łatwe. Wszystkie potrzebne do tego narzędzia są dostępne, więc to tylko kwestia wiedzy, których z nich użyć i jak je połączyć. Zastanówmy się więc, jak zbudować precyzyjny system powiadamiania o braku towaru.
KIEDY MAMY SKOMPLIKOWANY PROBLEM, który chcemy rozwiązać za pomocą uczenia maszynowego, pierwszym krokiem jest rozbicie tego problemu na sekwencję prostych zadań. Następnie możemy zastosować różne metody uczenia maszynowego, by rozwiązać cząstkę problemu zawartą w każdym z mniejszych zadań. Łącząc kilka małych rozwiązań w sekwencję otrzymamy system, który może zrobić coś bardziej skomplikowanego.
Oto jak możemy rozwiązać problem wykrywania pustych miejsc na wystawie:
Wejściem danych do uczenia maszynowego jest strumień wideo z normalnej kamery internetowej:

W ogólnym pojęciu prześlemy każdą klatkę wideo przez sekwencję różnych metod, po jednej klatce na raz.
Pierwszym krokiem w sekwencji jest wykrycie wszystkich możliwych miejsc, w których mogą znajdować się obiekty w kadrze. Wszakże musimy wiedzieć, które części obrazu są miejscami na produkty, zanim będziemy mogli wykryć, które z nich są wolne.
Drugim krokiem jest wykrycie wszystkich produktów w każdej klatce wideo. Pozwoli nam to na śledzenie ruchu i pozycję każdego produktu pomiędzy klatkami.
Trzeci krok to określenie, które z miejsc jest zajęte przez produkt, a które nie. Wymaga to połączenia wyników pierwszego i drugiego kroku.
OSTATNIM KROKIEM BĘDZIE WYSŁANIE powiadomienia, gdy miejsce na półce stanie się puste. Będzie się to opierało na zmianach pozycji produktów pomiędzy klatkami wideo.
Każdy z tych kroków możemy wykonać na wiele różnych sposobów, wykorzystując różne techniki. Nie ma jednego dobrego lub złego sposobu zbudowania tej sekwencji działań, a różne podejścia będą miały różne zalety i wady.
Załóżmy zatem, że widok z kamery jest mniej więcej taki:
Musimy być w stanie przeskanować szybko zdjęcie i wykryć te jego rejony, w których mogą leżeć produkty:

Najprostsze podejście polegałoby na „ręcznym” określeniu lokalizacji każdego miejsca zamiast prób ich automatycznego wykrywania. Niestety, jeśli kiedykolwiek przesuniemy kamerę lub będziemy chcieli wykryć miejsca na innej półce, będziemy musieli ponownie „ręcznie” zakodować nowe miejsca. Warto więc znaleźć automatyczny sposób wykrywania. Będzie to zróżnicowane, w zależności od przypadku. Na przykład w przypadku sklepu sensowne może być szukanie etykiet pod lub nad półką i założenie, że każda z nich ma przyporządkowane miejsce.

Ale to podejście wiąże się z pewnymi komplikacjami. Po pierwsze, nie każde miejsce ma etykietę, a sama etykieta nie mówi nam dokładnie, gdzie jest miejsce, a jedynie nas tylko trochę do niego przybliża. Nie mamy też kontroli nad tym, jak ktoś ustawi towar.
INNYM PROBLEMEM JEST ZBUDOWANIE MODELU detekcji obiektu, który szuka śladów miejsca narysowanych na półce (lub markerów), jak ten:

Niestety to podejście również nie jest w pełni satysfakcjonujące. Po pierwsze, ze względów estetycznych markery najpewniej będą naprawdę małe i trudno je dostrzec pod każdym kątem i w zmieniającym się oświetleniu – więc tym bardziej trudno będzie je wykryć przy pomocy komputera. Dodatkowo nasz przykładowy kadr jest pełen różnych niezwiązanych ze sobą linii kolorów i znaków. Trudno będzie oddzielić te, które są miejscami, od tych, które są przegrodami, etykietami, fragmentami produktów itd.
Zawsze gdy mamy taki problem, który wydaje się trudny, warto poświęcić kilka minut na sprawdzenie, czy potrafimy wymyślić inny sposób rozwiązania do problemu, który omija niektóre z wyzwań technicznych. Czym jest miejsce na półce? To tylko przestrzeń, w której produkt znajduje się przez długi czas. Być może nie musimy w ogóle wykrywać miejsc? Dlaczego nie możemy po prostu wykryć produktów, których nikt nie przemieszcza przez dłuższy czas, i założyć, że znajdują się na miejscach?

Ramka wokół przedmiotów to de facto nasze miejsce.
WYKRYWANIE OBIEKTÓW W KADRZE WIDEO jest problemem dobrze już opisanym w literaturze. Istnieje wiele metod uczenia maszynowego, które możemy wykorzystać do wykrycia obiektu na obrazie. Oto niektóre z najczęściej spotykanych algorytmów wykrywania obiektów, w kolejności od nieco starszych do współczesnych:
- Wytrenowanie wykrywacza obiektów HOG (Histogram Oriented Gradients) i przesuwanie go nad naszym obrazem, by znaleźć wszystkie obiekty. To starsze, niekorzystające z głębokiego uczenia podejście jest stosunkowo szybkie, ale nie radzi sobie z różnorodnością obiektów;
- Wytrenowanie detektora obiektów CNN (Convolutional Neural Network) i przesuwanie go nad naszym obrazem, aż znajdziemy wszystkie produkty. Takie podejście jest dokładne, ale nie aż tak skuteczne, ponieważ musimy wielokrotnie skanować ten sam obraz za pomocą CNN, aby znaleźć wszystkie obiekty w całym obrazie. I choć może łatwo znaleźć rzeczy o dużej różnorodności, wymaga znacznie więcej danych treningowych niż detektor obiektów oparty na HOG;
- Wykorzystanie nowszych podejść korzystających z głębokiego uczenia, takich jak połączenie maski z CNN (Mask R-CNN ), Faster R-CNN lub YOLO, które łączy dokładność sieci CNN z inteligentnym projektowaniem i sztuczkami wydajności znacznie przyspieszającymi proces wykrywania. Będzie to działać stosunkowo szybko (na GPU), o ile będziemy mieli dużo danych treningowych.
OGÓLNIE RZECZ BIORĄC, PRZY WDROŻENIU chcemy wybrać najprostsze rozwiązanie, które wykona zadanie przy najmniejszej ilości danych treningowych, jednocześnie nie zakładając, że potrzebujemy najnowszego, najbardziej innowacyjnego algorytmu. W tym konkretnym przypadku metoda Mask R-CNN jest rozsądnym wyborem, mimo że jest relatywnie nowa.
Architektura Mask R-CNN jest zaprojektowana w taki sposób, że wykrywa obiekty na całym obrazie w sposób wydajny obliczeniowo, bez stosowania podejścia „przesuwanego okna”. Dzięki nowoczesnemu procesorowi graficznemu powinniśmy być w stanie wykrywać obiekty w filmach o wysokiej rozdzielczości z szybkością kilku klatek na sekundę. To powinno być w wystarczające w przypadku tego zastosowania.
Dodatkowo, Mask R-CNN daje nam wiele informacji o każdym wykrytym obiekcie. Większość algorytmów detekcji obiektów zwraca tylko pole ograniczające każdego obiektu. Ale Mask R-CNN nie tylko poda nam lokalizację każdego obiektu, ale również da nam zarys obiektu (maskę).
Aby wytrenować model Mask R-CNN, potrzebujemy mnóstwa zdjęć z różnymi rodzajami obiektów, które chcemy wykrywać. Moglibyśmy ręcznie zrobić zdjęcia obiektów i prześledzić wszystkie rzeczy na tych zdjęciach, ale zajęłoby to bardzo dużo czasu. Na szczęście, nasze obiekty to rzeczy, które wiele osób chce wykryć. Istnieje więc szansa, że są one już dostępne w publicznych zbiorach.
Istnieje popularny zbiór danych COCO (skrót od Common Objects In Context), który zawiera obrazy opatrzone maskami obiektów. W tym zbiorze danych znajduje się ponad 120 tysięcy obrazów z już zarysowanymi 880 tysiącami obiektów. Oto jeden z obrazów w zbiorze danych COCO:

Dane te są idealne do treningu modelu Mask R-CNN.
Ale sprawy mają się jeszcze lepiej. Wykrywanie obiektów przy użyciu zestawu danych COCO jest tak popularne, że wiele osób już to zrobiło i podzieliło się swoimi wynikami. Więc zamiast trenować nasz własny model, możemy zacząć od wstępnie przeszkolonego modelu, który już może wykrywać obiekty. W tym przykładzie wykorzystamy implementację Mask R-CNN firmy Matterport, która jest dostarczana ze wstępnie wytrenowanym modelem.
JEŚLI URUCHOMIMY WSTĘPNIE WYTRENOWANY model na naszym obrazie z kamery, to jest to, co jest wykrywane po przysłowiowym „wyjęciu z pudełka”:

Nie tylko identyfikujemy produkty, ale także takie rzeczy, jak światła, półki, ludzie w tle itp. Oczywiście zdarzają się błędy.
Dla każdego obiektu wykrytego na zdjęciu, otrzymujemy z modelu Mask R-CNN cztery rzeczy:
- Typ obiektu, który został wykryty (jako liczba całkowita). Wstępnie przeszkolony model COCO wie, jak wykryć 80 różnych wspólnych obiektów; https://gist.github.com/ageitgey/b143ee809bf08e4927dd59bace44db0d
- Wynik pewności w wykrywaniu obiektów. Im wyższa liczba, tym większa pewność, że model poprawnie rozpoznaje obiekt;
- Pole ograniczające obiektu na obrazie, podane jako lokalizacje pikseli X/Y;
- Bitmapowa „maska”, mówiąca, które piksele w ramce ograniczającej są częścią obiektu, a które nie. Z danymi maski możemy również opracować kontur obiektu.
OTO KOD W JĘZYKU PYTHON do wykrywania pól ograniczających przy użyciu wstępnie wyszkolonego modelu z implementacji Matterport’s Mask R-CNNN wraz z OpenCV:
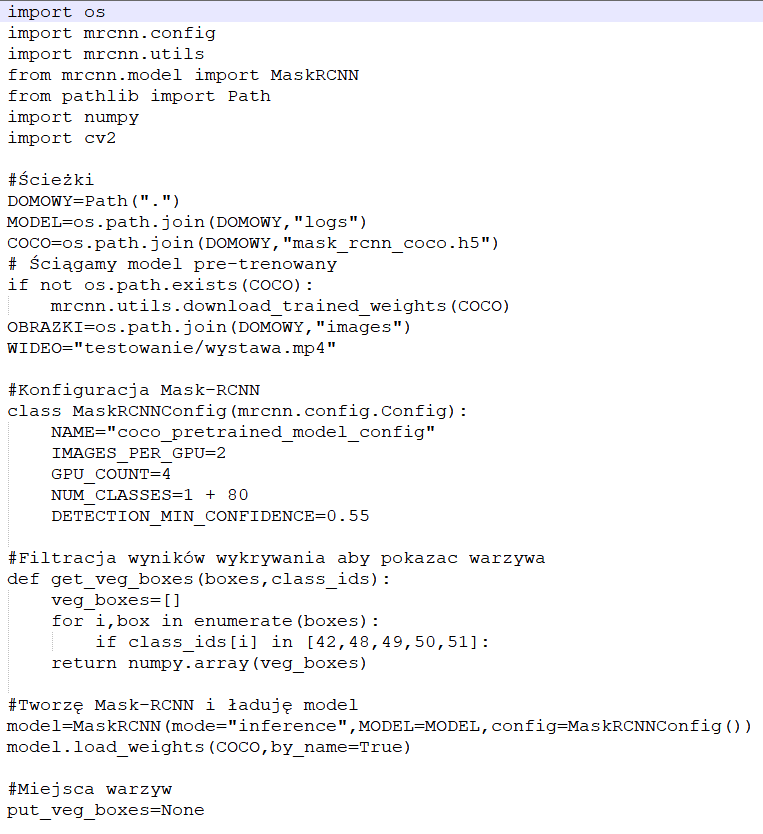

Aby uruchomić ten kod, musimy najpierw zainstalować Python 3.6+, Matterport Mask R-CNN i OpenCV.
KIEDY URUCHOMIMY TEN SKRYPT, na ekranie pojawi się obraz z prostokątem wokół każdego wykrytego obiektu. W ten sposób na konsoli otrzymamy również współrzędne pikseli każdego wykrytego obiektu.

Po tym wszystkim udało nam się wykryć obiekty na zdjęciu. Przejdźmy do następnego kroku. Skoro znamy lokalizację pikseli każdego obiektu na naszym zdjęciu i patrząc na wiele klatek wideo z rzędu, możemy łatwo określić, które obiekty nie zostały przeniesione, i założyć, że są to miejsca na półkach. Ale jak wykryć, kiedy obiekt opuszcza swoje miejsce. Problem polega na tym, że niekiedy ramki ograniczające przedmioty na naszym zdjęciu częściowo się na siebie nakładają:

Jeśli więc założymy, że każdy z tych ograniczników reprezentuje miejsce, możliwe jest, że może być częściowo zajęty przez przedmiot nawet wtedy, gdy miejsce jest puste. Potrzebujemy sposobu zmierzenia, na ile dwa obiekty na siebie zachodzą, aby można było sprawdzić, czy nie ma pozornie pustych miejsc. Miara, której będziemy używać, nosi nazwę Intersection Over Union (IoU). IoU oblicza się poprzez znalezienie ilości pikseli, w których dwa obiekty nakładają się na siebie i dzieląc ją przez ilość pikseli pokrytych przez oba obiekty, jak ten:
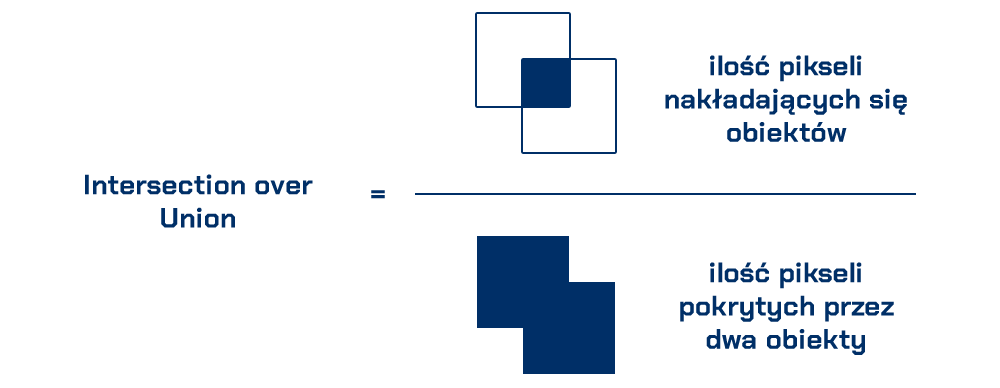
Pozwoli nam to zmierzyć, w jakim stopniu ogranicznik przedmiotu nakłada się na ogranicznik sąsiadującego miejsca. Dzięki temu możemy łatwo stwierdzić, czy obiekt znajduje się na miejscu, czy nie. Jeśli miara IoU jest niska, jak 0.20, oznacza to, że obiekt nie zajmuje dużo miejsca. Ale jeśli miara jest wysoka, jak 0.5, oznacza to, że obiekt zajmuje większość miejsca, więc możemy być pewni, że miejsce to jest zajęte.
Ponieważ IoU jest tak powszechną miarą, często biblioteki, z których korzystamy, będą już miały jego implementację. I w rzeczywistości biblioteka Matterport Mask R-CNN zawiera ją jako funkcję zwaną compute overlaps, więc możemy po prostu użyć tej funkcji.
Zakładając, że mamy listę ograniczników reprezentujących obszary miejsc na naszym obrazie, sprawdzenie, czy wykryte obiekty znajdują się wewnątrz tych ograniczników, jest tak proste, jak dodanie linii lub dwóch kodu:
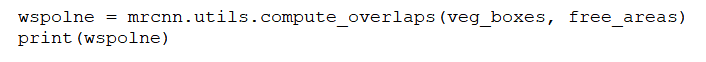
Wynik wyglądać może tak:
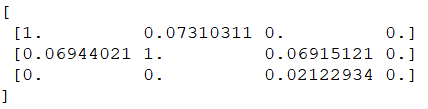
W TAKIEJ MACIERZY KAŻDY RZĄD REPREZENTUJE jeden z ograniczników miejsc. Podobnie, każda kolumna przedstawia, w jakim stopniu miejsca zostały nałożone na siebie przez jeden z wykrytych obiektów. Wynik 1.0 oznacza, że obiekt całkowicie zajmuje miejsce, a niski wynik, jak 0.02, oznacza, że obiekt dotyka miejsca, ale nie zajmuje większości obszaru. Aby znaleźć niezajęte miejsca, wystarczy sprawdzić każdy rząd w tej macierzy. Jeśli każda liczba to zero lub wszystkie są naprawdę małe, oznacza to, że nic nie zajmuje tego miejsca i dlatego musi być ono wolne.
Należy jednak pamiętać, że wykrywanie obiektów nie zawsze działa idealnie w przypadku wideo na żywo. Nawet jeśli Mask R-CNN jest bardzo dokładny, czasami może zabraknąć obiektu lub dwóch w jednej klatce filmu. Zanim więc oznaczymy miejsce jako wolne, powinniśmy się upewnić, że pozostanie ono wolne przez jakiś czas – np. 15 kolejnych klatek wideo. Zapobiegnie to nieprawidłowemu wykrywaniu przez system wolnych miejsc tylko dlatego, że wykrywanie obiektów zawiodło na jednej klatce wideo.
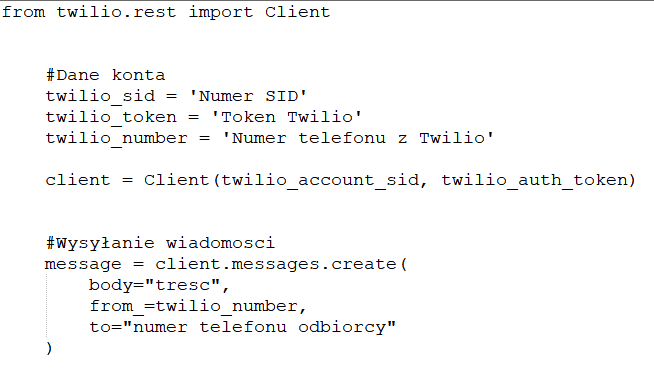
Ostatnim krokiem naszego systemu jest wysłanie powiadomienia SMS, gdy zauważymy, że miejsce jest wolne dla kilku klatek wideo. Wysyłanie wiadomości SMS z Pythona jest bardzo proste przy użyciu Twilio. To popularny API, pozwalający wysłać wiadomość SMS z praktycznie dowolnego języka programowania kilkoma liniami kodu. Oczywiście, możliwe jest używanie innego dostawcy usług SMS.
Aby korzystać z Twilio, należy zarejestrować konto próbne, utworzyć numer telefonu Twilio i uzyskać dane uwierzytelniające konto. Następnie musimy zainstalować bibliotekę kliencką Twilio Python:

Z ZAINSTALOWANYM PAKIETEM CAŁY KOD do wysłania wiadomości SMS w Pythonie zaprezentowany jest poniżej – wystarczy, że zastąpisz wartości danymi swojego konta.
Aby dodać możliwość wysyłania wiadomości SMS do naszego skryptu, możemy po prostu wrzucić ten kod bezpośrednio do środka. Ale musimy uważać, aby nie wysyłać sobie wiadomości tekstowych na każdej klatce nowego filmu, gdzie wolne miejsce jest wciąż wolne. Będziemy więc musieli mieć flagę do śledzenia, czy wysłaliśmy już wiadomość SMS i upewnić się, że nie wyślemy kolejnej, dopóki nie minie określony czas lub dopóki nie zostanie wykryte inne miejsce, które jest wolne.